Vulnerability Management Program - How to implement SLA and its processes
Defining good SLAs is a tough challenge, but it’s at the heart of any solid vulnerability management program. This article helps internal security teams set clear SLAs, define the right metrics, and adjust their ticketing system to build a successful vulnerability management program.

If you're part of an internal security team working to build a strong vulnerability management program, this article (and the full series on the topic on my blog) is for you.
Defining good SLAs is a hard problem, but it’s at the core of your vulnerability management program.
Your program requires accountability from engineers and other departments to remediate vulnerabilities. Clearly defined SLAs and their associated processes are critical to achieving success.
They will help you establish realistic timelines for remediation, quickly identify teams that struggle with vulnerabilities, and highlight those producing the most issues. Most importantly, effective SLAs will provide actionable metrics to continually enhance your Product Security program, improve overall quality, and build resilience within your organization.
An SLA might seem straightforward, just pick a number of days and you're done, right? In reality, defining effective SLAs is much more complex.
First, here are a few requirements before defining your SLA:
- Your SLA needs to reflect realistic timelines that align with your engineering and development teams' ability to remediate vulnerabilities.
- You need to accept that your SLAs will evolve over time after you tested them.
- Expect a few quarters of adjustment to get it right. And then keep refining them.
- Your SLAs must be defined in collaboration with your compliance team to ensure they align with existing obligations such as SOC2, ISO standards, vendor and client contracts, banking regulations, and any other requirements that mandate vulnerability remediation.
- If you’re required to fix critical severity issues within N days, your SLA processes must align with that obligation. If they don’t, you’ll need to renegotiate those contracts. That's another reason to work closely with your compliance team.
- Your compliance or GRC team must maintain a risk matrix or an equivalent to define the severity of issues within your organization. It should look like the following graphic:
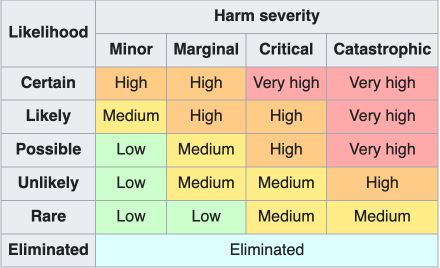
- Each likelihood and impact (harm in this example) level needs a description of what it really means:
- Financial impact (in dollar value)
- Reputation impact (e.g., number of clients lost, media exposure)
- System downtime (duration and scope)
- Severity of the affected systems or services
- etc.
- Your GRC team needs a clear risk acceptance process along with a risk registry that is reviewed and approved at the board level.
- You need a ticketing system such as Jira or similar with a dedicated "Vulnerabilities" board to list all technical vulnerabilities.
- Optional to start your program, but HIGHLY recommended: Categorization of all your systems, applications, services, and assets.
- Define a severity (risk) level - Based on the risk matrix above.
- Identify your Crown Jewel - If this asset goes down, the company is in a bad position (money, reputation, etc.)
Main steps of implementation
The following sections explain which type of tickets, tag, labels and data you need in your ticketing system to automate and scale your vulnerability management program and processes.
SLA
- Define the SLA values by severity. Suggested values:
- Critical*: 5-15 days
- High: 15-45 days
- Medium: 60-90 days
- Low: 180+ days (or tracked as tech debt)
*Note: Critical vulnerabilities requires that your teams start working on it from day one!
Workflows
- Create the workflow in Jira or your ticketing system.
- Standardize ticket lifecycle (ticket status):
- Open → Triage → In Progress or Assigned (when assigned) →
- Mitigated* - A partial fix is in place, but it is not remediated.
- Now you have to adjust the severity and the due date to reflect the new severity.
- Mitigated* - A partial fix is in place, but it is not remediated.
- Open → Triage → In Progress or Assigned (when assigned) →
- Standardize ticket lifecycle (ticket status):
- Example: If the issue was critical with a 5-day SLA and is mitigated to Medium severity (60 days) on day 3, the new due date becomes 60 – 3 days, adjusted based on time already spent before mitigation.
- Verified (if needed) - Confirmation that the issue is fixed → Closed
- Closed
- As Fixed
- As Informative
- As Risk Accepted
After the workflow is completed, you will need to add more fields in your ticketing system. This will help you get better metrics, improve your program, and provide insightful reports to leadership/the board.
*Note: A mitigated vulnerability is not fixed, its risk is only reduced. Your tickets and processes must reflect that reality and handle it accordingly.
Custom Fields - Improvements
- Create the following fields
- To track severity changes:
- Original Severity
- Current Severity (post-triage - helps see change of severity over time after triage assessments)
- Reporter (who found/reported the vuln)
- Source (e.g. bug bounty, pentest, code scanning, SCA, cloud scanner, or any other program that generate findings for you.)
- Affected Asset(s) or System(s)
- URL Endpoint affected (if a Web or API endpoint)
- Will help correlate owner, to repositories to the URL endpoints
- Business Owner (who or which team owns the system/endpoints)
- Due Date (End of SLA countdown)
- You need to be able to change the value when severity change on mitigation or adjustment of severity after triage.
- Optional
- Date Reported (Start of SLA countdown)
- Your ticketing system should have this date and time by default on ticket creation.
- SLA Status (On Track / At Risk / Breached)
- You have a due date, severity, and start date, so you should already know the status—but add a field to clearly show it.
- You can define the specific time before the end of the SLA to be "at risk" depending on how much time engineering usually requires.
- Root Cause Analysis - You can add a field that links to the documentation or PR that introduced the issue.
- Just keep in mind: identifying the root cause or when the issue was introduced can take significant time.
- Date Reported (Start of SLA countdown)
- To track severity changes:
Labels and Tags
- Create labels and tags (optional, but helpful to improve metrics, dashboard and automation).
- Labels (used for workflow/status management):
-
sla-critical,sla-high,sla-violated,risk-accepted,needs-triage,extension-requested
-
- Tags (used for filtering/classification):
source:bugbounty,source:scanner,source:pentest, etc.asset:billing-api,asset:internal-tool, etc.team:frontend,team:platform, etc.pentest-name-vendorName-month-yearinternal-test-appname-month-year
- Labels (used for workflow/status management):
Access Control
- Define workflows and access controls
- Restrict critical vulnerability tickets from being seen by everyone.
- Make sure to have a field to "add employee/group X" to be able to view the restricted tickets.
- Have the option to restrict any tickets, in case of severity change.
- Add a "Visibility Exception" field to include specific employees or groups.
- Allow the security team to downgrade visibility dynamically if severity changes.
- Every engineers and their leadership should have access to the vulnerability board and its metrics dashboards.
Automation
To improve communication around vulnerability management, you’ll need several automations. Start by setting up one in your ticketing system that tags the ticket owner and all involved parties when the ticket is created and when the SLA is close to expiring.
- Configure automated reminders
- 1 week before SLA is ending (high).
- 1 month before SLA is ending (medium).
- 2-4 months before SLA is ending (low).
- Weekly SLA breach reports for all overdue tickets.
- Tag a security team member when:
- A ticket assignee account is deactivated (left the company).
- A ticket have no assignee after being open for N hours.
- No follow up after N days after the ticket was assigned.
Once that's in place, it's highly recommended to set up the same automation in your communication systems (Slack, Teams, etc.), sending a private message to the owner and/or a public message in the vulnerability management channel of the team with an SLA nearing expiration or when a ticket is assigned.
Metrics and their usage
You also want metrics not just to report to leadership, but to improve your program and guide training efforts by focusing on the right teams, like those with a high number of vulnerabilities or recurring issues of the same type.
These metrics can live in a dashboard within your ticketing system or any other platform. As long as accessing the data is easy and quick to access for leadership or cross-functional teams.
- Metrics accessible by leadership and xfn-teams:
- Track SLA compliance % by team and severity
- Follow vulnerability trends per type, per teams, per application, per system, etc.
- This will let you train the right teams on the right issues.
- Leadership should see those metrics monthly.
- Monitor the number of extended SLA or accepted risks tickets
- Report weekly and monthly to Security/GRC/Product teams lead
- Quarterly reports of critical severity issues to the board, along with the reasons why they happened and how they are being fix.
- Iterate and improve
- Review SLA and workflows every quarter or two
- Adjust the time based on engineering feedback and real-world data
- If your team can't handle a 5 day critical, make it longer, but don't forget to align with all your contracts and compliance requirements and obligations or vice versa.
- Do a post-mortem for
- Every critical issue. Do the same for highs severity when bandwith allows you to.
- Breached SLA on Critical/High severity vulnerability ticket to improve your triage process and your team's responsibilities.
- Review SLA and workflows every quarter or two
Communication
A good approach, alongside automation, is to create a dedicated channel (on Slack, Teams, etc.) that tags the right teams or owners when a new vulnerability ticket is created and when an SLA is about to be missed (a few days or weeks in advance).
Make sure to send monthly or quarterly reports by email and hold meetings with xfn-team managers to gather feedback and understand how they feel about the process. Validate if there’s any friction or anything that could be improved from a communication or process standpoint.
Meet and report monthly to security leadership for the same reasons, and to highlight where the company’s main risks are based on vulnerability trends. Which applications are most at risk because they:
- Have too many vulnerabilities
- Contain the highest number of critical and high-severity issues
- Repeatedly produce the same types of problems
- Etc.
Operationalize
Now that your ticketing system is set up, it’s time to focus on how to run the program.
A solid way to manage vulnerabilities is by setting up an “on-call” rotation within your team. Each team member takes on-call duties every other weeks, depending on team size. Ex: a team of 7 will do one on-call week every 7 weeks.
The on-call person receives all notifications of new vulnerabilities from all your programs and creates the vulnerability ticket or they get created automatically in your ticketing system.
The on-call process
When a new vulnerability ticket is created, they will:
- Assign it to the owner of the application/asset
- Automation will notify the owner or their team.
- Validate if it's a false positive or a duplicate
- Usually this is done only for automated tools and bug bounty
- Review/define the severity level and adjust the ticket if needed
- Bug bounty researchers will often assign a higher severity than justified - to get more money ;)
- If needed - Be available for helping the engineers to review the severity and the fix.
- Optional (or when the process is mature) - Review the all critical-severity and eventually high-severity fixes produced by the engineers before pushing them back in production.
On-call Metrics
It is also really important to have operational metrics for your on-call team managing vulnerabilities. These metrics help confirm whether team members can realistically handle on-call duties while still progressing on their own projects or not.
They’re also a strong signal for burnout. If your team can't keep up with the vulnerabilities, SLAs, or your processes, you'll need to adapt or re-prioritize tasks both in projects and in your vulnerability management workflows.
These metrics will also help you improve remediation speed, owner assignment, and more. They’ll show you where automation can make a difference like tagging the right people, auto-assigning ownership, or integrating with asset services.
Conclusion
Now that you’ve got a ticketing board for vulnerabilities and a handle on your metrics, the next step is prioritizing which vulnerabilities to fix first.
That prioritization needs to reflect both the severity of the vulnerabilities and the criticality of the affected assets or systems. Example: you’ll always fix a critical vulnerability in a critical system before fixing the same severity in a low-impact system.
To get this right, go back to your corporate (or compliance) risk matrix and your asset inventory.
Based on those risks, you decide which vulnerabilities actually need action and how fast. That’s where your SLA meets reality.
- You no longer treat all findings equally. As discussed in our previous article "Millions of Vulnerabilities: One Checklist to Kill The Noise".
- You patch what matters, accept what’s reasonable and track the rest transparently.
- You adjust your SLAs with input from engineering, compliance and security leadership.
- You improve and fine-tune your Vulnerability Management processes.
Over time, your SLAs, your metrics, and your workflows will turn vulnerability chaos into a structured risk program: your vulnerability management program.
P.S: Thanks to Maxime F. for his thoughts and insights into the metrics and the ticketing systems technicalities.



